

The focus of this article is on my recent service request issue. A customer reported an error at the cluster level, indicating that the vSphere DRS functionality was affected by an unhealthy state of the vSphere Cluster Services, caused by the unavailability of vSphere Cluster Service VMs.
The vSphere Cluster Service VMs play a crucial role in maintaining the health of vSphere DRS. Additionally, the cluster service health was also reported as unhealthy. You can refer to the screenshot below for a similar view:
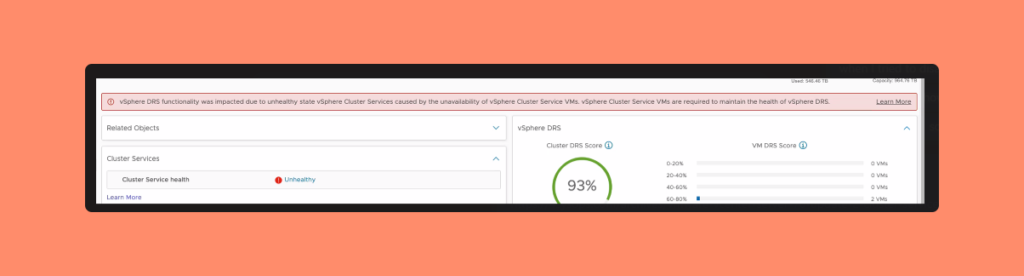
Alright, now that we have identified the issue, let’s explore the solution. First and foremost, let’s gain an understanding of vCLS – what it is and why it holds significance.
vSphere Cluster Services (vCLS) is a novel addition to vSphere 7.0 Update 1. Its primary purpose is to ensure the availability of critical cluster services, such as vSphere DRS (Distributed Resource Scheduler) and vSphere HA (High Availability), even if the vCenter Server instance is temporarily unavailable. This guarantees the uninterrupted management of resources and the health of workloads operating within the clusters, regardless of the vCenter Server’s status.
Table of Contents
Troubleshoot #1:
To access the cluster level in vCenter, log in to your vCenter Server and follow these steps:
- Navigate to the closure level by clicking on the desired cluster.
- Next, click on the “Config” tab.
- Within the “Config” tab, locate the option to enable or disable DRS (Distributed Resource Scheduler).
- If the DRS is currently enabled, click on the corresponding button or checkbox to disable it.
- After disabling DRS, observe if the issue you were experiencing persists.
Please keep in mind that if your environment contains vApps, it is not possible to disable DRS as it may be required for the proper functionality of vApps.
Troubleshoot #2:
In my case above steps won’t work, now let’s jump to the next steps. This step will put our cluster in retreat mode
- Access the vSphere Client and log in.
- Find the cluster where vCLS needs to be disabled and select it.
- Copy the cluster domain ID from the URL in the browser. The ID should resemble domain-c(number).
- Navigate to the Configure tab for vCenter Server.
- Click on Advanced Settings, then select Edit Settings.
- Add a new entry with the name config.vcls.clusters.domain-c(number).enabled and paste the copied domain ID from step 3.
- Set the value to False.
- Click Save to apply the changes.
Make sure to only copy the numbers before the colon in the URL. Once the cluster is in retreat mode, monitor the vCLS summary by accessing the vCenter monitoring tab located at the bottom of the screen. After one or two minutes, exit retreat mode by changing the parameter value to true.
Troubleshoot #3:
If the previous steps do not work, the next course of action involves three steps. It’s important to note that vCLS VMs require a datastore to store their files and data. This step involves verifying the presence of a datastore, and adding one if none exists.
- Log in to vCenter.
- Go to the Config tab at the cluster level, and navigate to Datastore under vCenter Cluster Services.
- Check if a datastore is already added there. If not, add a common datastore that has access to all VMs.
- Once enabled, wait for a couple of hours and check the status of the vCLS VMs.
Troubleshoot #4:
After adding the data store, wait for a couple of hours. If the issue persists, consider rebooting the VC and checking the status of the vCLS VMs. If any vCLS VMs are in a powered-off state, try powering them on. In my case, powering on the vCLS VMs also creates other vCLS VMs that are responsible for maintaining the health of the vSphere Cluster Service.
If you have followed all the steps and are still experiencing issues, it may be necessary to check the EAM and VMON logs to further narrow down the issue for troubleshooting. If you have any additional thoughts or suggestions, please feel free to leave a comment. Additionally, if you require further assistance, you can reach out to me on Twitter.




Thanks, the second method helped me, with a temporary shutdown.
Thanks Sten, Great it helped for you